
Adversarial Machine Learning: The Next Evolution in Cyber Warfare?
How Adversarial Machine Learning is Changing the Landscape of Cybersecurity?

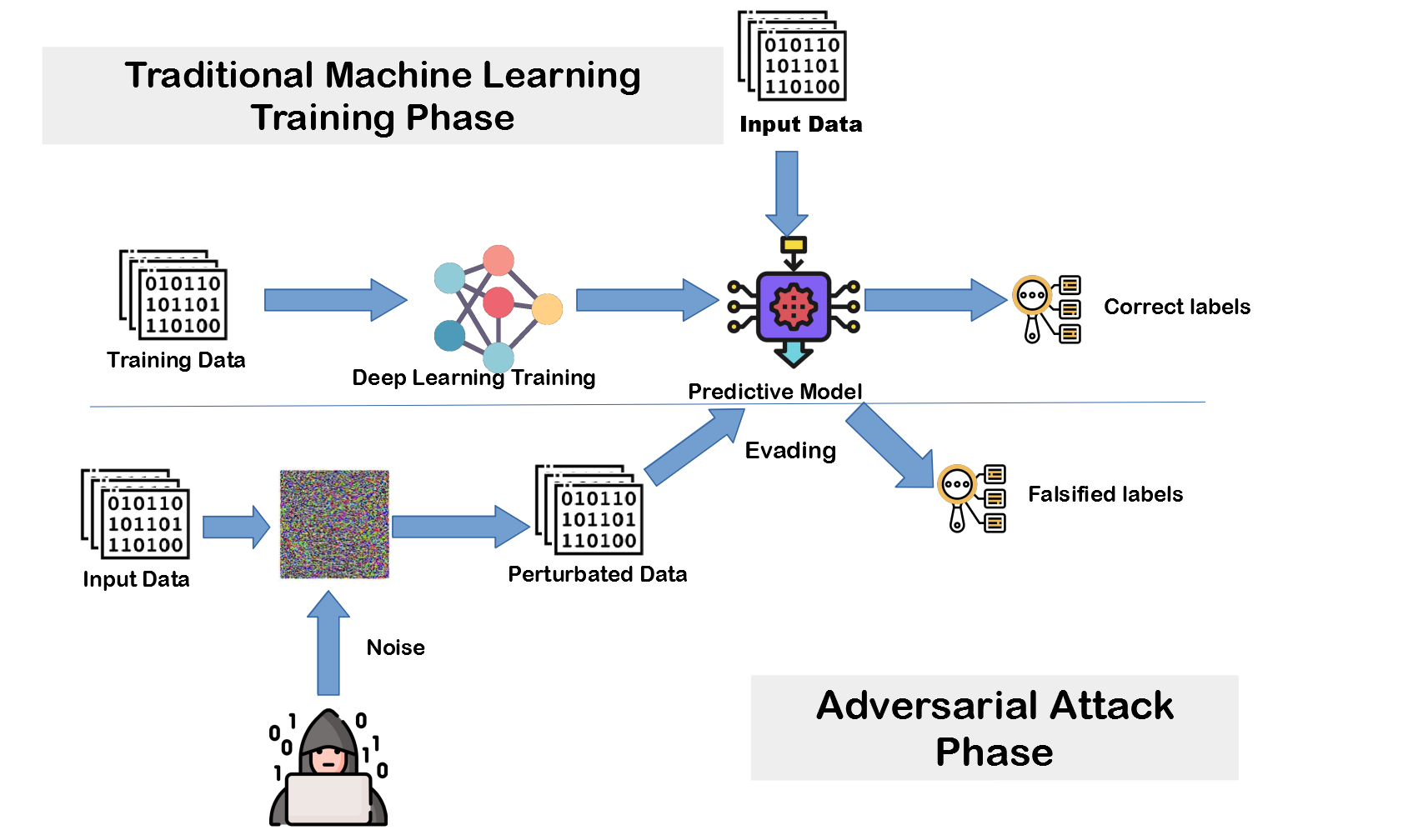
Adversarial Machine Learning is the study of assaults on machine learning systems as well as their defences. It is a set of approaches for teaching neural networks to detect purposefully deceptive data or behaviour. Adversarial machine learning is an increasing concern in AI and machine learning Because this is a technique that seeks to trick algorithms with fraudulent data. As a result, it comprises both the production and detection of adversarial instances, which are inputs explicitly designed to fool classifiers.
Adversarial machine learning attacks have been intensively researched in fields such as image classification and spam detection. The most comprehensive investigations of adversarial machine learning have been undertaken in the field of image recognition, where visual alterations induce a classifier to give inaccurate predictions.
To understand, remember that most machine learning approaches are designed to operate on certain problem sets, assuming that the training and test data come from the same statistical distribution. However, in real high-stakes applications, this assumption is frequently critically broken since users may actively submit false data that violates the statistical assumption.
This varies from the conventional classification issue in machine learning in that the objective is to identify weaknesses and create more flexible learning algorithms rather than simply detecting "poor" inputs.

{kind=link}
What is an adversarial example?
An adversarial example is an input (such as an image or sound) that is intended to induce a machine-learning model to make an incorrect prediction. It is created from a clean example by introducing a minor disturbance undetectable to humans but detectable by the model.
Researchers demonstrated that deep learning systems might be fooled by modifying just one pixel.
Examples:
Examples include spam filtering attacks, in which spam messages are obfuscated by misspelling "bad" words or inserting "good" words; computer security attacks, such as obfuscating malware code within network packets or modifying the characteristics of a network flow to mislead intrusion detection; and biometric recognition attacks, in which fake biometric traits may be exploited to impersonate a legitimate user or compromise users' template galleries.
Evasion attacks, data poisoning assaults, Byzantine attacks, and model extraction are some of the most prevalent adversarial machine learning threat models.
Nilesh Dalvi and colleagues discovered in 2004 that linear classifiers used in spam filters might be beaten by simple "evasion attacks" in which spammers inserted "good phrases" into their spam emails. (Some spammers introduced random noise to blur text inside "image spam" about 2007 in an attempt to bypass OCR-based filters.)
Furthermore, researchers such as Google Brain's Nicholas Frosst point out that physically removing the sign itself, rather than just producing hostile instances, makes it far easier to make self-driving cars miss stop signs.
Frosst also feels that the adversarial machine learning community wrongly expects that models trained on one data distribution would perform well on another. He believes that a novel method of machine learning should be investigated, and he is now working on a novel neural network with properties more akin to human perception than existing techniques.
While adversarial machine learning remains deeply rooted in academia, large tech companies such as Google, Microsoft, and IBM have begun curating documentation and open-source code bases to enable others to concretely assess the robustness of machine learning models and reduce the risk of adversarial attacks.
How to Attack and Defend ML Models?
Machine learning models in computer vision are now employed in a wide range of real-world applications, including self-driving vehicles, facial recognition, and cancer detection. Modern computer vision models are built on deep neural networks with up to several million parameters and rely on hardware that was not accessible even a decade ago. The rising accuracy of these machine learning systems has inevitably resulted in a flood of applications that use them. Getting incorrect predictions from a machine learning model used to be the norm a few years ago.
As they are increasingly used in real-world circumstances, security flaws caused by model inaccuracies have become a major worry.
Attack modalities
Attacks against (supervised) machine learning algorithms have been classified into three categories: effect on the classifier, security breach, and specificity.
1. Classifier influence: A classifier can be influenced by disturbing the classification process. An exploratory step to uncover vulnerabilities may precede this. The inclusion of data modification limitations may limit the attacker's capabilities.
2. Security breach: An assault might provide harmful material that is mislabelled as legitimate. Malicious data provided during training may result in valid data being rejected after training.
3. Specificity: A targeted assault seeks to permit a specific intrusion/disruption. An indiscriminate attack, on the other hand, causes widespread devastation.
This taxonomy has been expanded into a complete threat model, including explicit assumptions about the adversary's aim, knowledge of the attacked system, capacity to manipulate input data/system components, and assault technique. This taxonomy has been expanded to include dimensions for adversarial assault defensive techniques.

{kind=link}
Defences Against Adversarial Examples
The attacker creates the attack by utilising all of the model's information. Obviously, the less information the model produces at prediction time, the more difficult it is for an attacker to devise a successful assault.
One simple way to safeguard your classification model in a production setting is to avoid displaying confidence scores for each projected class. The model should instead just offer the top Neural Networks (e.g., 5) most probable classes. Because when the end user is given confidence scores, a malicious attacker can utilise these to calculate the gradient of the loss function. As a result, attackers can create white-box attacks, such as the rapid gradient sign approach. The authors of the Computer Vision Foundation work we mentioned previously describe how to conduct this against a commercial machine-learning model.
Let's take a look at two possible defences in the literature.
Machine Learning Adversarial Defences
The most effective methods for training AI systems to survive these threats fall into two categories:
1. Adversarial training- This is a brute force supervised learning strategy in which the model is fed as many adversarial cases as possible that have been expressly classified as threatening. This is the same technique that most antivirus software used on desktop PCs does, with daily updates.
While extremely successful, it requires ongoing maintenance to keep up with emerging threats and still suffers from the fundamental limitation that it can only prevent something that has already happened from happening again.
2. Defensive distillation- This method increases the flexibility of an algorithm's classification process, making the model less vulnerable to abuse. To stress accuracy, one model is trained to predict the output probabilities of another model that was trained on an earlier baseline standard.
The distillation strategy has the greatest benefit of being flexible to unexpected dangers. Distillation, while not completely proven, is more dynamic and requires less human involvement than adversarial training.
The main drawback is that while the second model has more leeway in rejecting input manipulation, it is still constrained by the first model's basic principles. As a result, given sufficient computational power and fine-tuning on the side of the attacker, both models may be reverse-engineered to identify basic vulnerabilities.
Conclusions and Further Steps
What Comes Next? Machine learning introduces a new attack surface and raises security threats by allowing for data manipulation and exploitation. Organisations that implement machine learning technology must plan for the possibility of data corruption, model theft, and adversarial samples.
That’s why Attacking a machine learning model is now simpler than protecting it.
If no defence strategy is used, state-of-the-art models implemented in real-world applications are readily deceived by hostile instances, opening the door to potentially serious security vulnerabilities. Hostile training is the most dependable protection approach, in which adversarial instances are produced and added to clean examples throughout training.
I advocate using the open-source Python module CleverHans to test the resilience of your image classification models to various assaults. Many attack methods, including those listed in this article, can be evaluated against your model. This module may also be used to do adversarial training on your model to strengthen its resilience against adversarial samples.
Finding new assaults and improved protection tactics is an ongoing scientific project. More theoretical and empirical research is needed to improve the robustness and safety of machine-learning models in real-world applications.
I urge you to try these strategies and share your findings, there is a need to identify and address the threat to the advancement in upcoming machine learning technology.
This article was originally published on the company blog.
Intellicy is a consultancy firm specialising in artificial intelligence solutions for organisations seeking to unlock the full potential of their data. They provide a full suite of services, from data engineering and AI consulting to comment moderation and sentiment analysis. Intellicy's team of experts work closely with clients to identify and measure key performance indicators (KPIs) that matter most to their business, ensuring that their solutions generate tangible results. They offer cross-industry expertise and an agile delivery framework that enables them to deliver results quickly and efficiently, often in weeks rather than months. Ultimately, Intellicy helps large enterprises transform their data operations and drive business growth through artificial intelligence and machine learning.